[기술서적 리뷰] Clean Architecture - 5. 아키텍처 (ch.23 ~ 26)
Chapter 23. 프레젠터와 험블 객체 (Humble Object)
앞장에서 설명한 프레젠터는 험블 객체 패턴을 따른 형태로, 아키텍처 경계를 식별하고 보호하는데 도움이 된다.
험블 객체 패턴
테스트하기 어려운 부분과 테스트하기 쉬운 부분을 분리하기 위해 험블 객체 패턴이 고안되었다.
코드 집합을 두가지 모듈로 분리할 수 있다. 가장 기본적인 핵심, 테스트하기 쉬운 부분을 한 모듈에 남기고, 나머지 테스트하기 어려운 부분은 험블 객체에 담는다.
예를 들면 GUI의 경우 화면 속 요소가 적절히 위치되었는지 테스트하기 어렵다. 반면 이외의 화면에서 수행되는 로직, 이벤트는 테스트하기 쉽다. 험블 객체 패턴을 사용하여 이 두가지 부분을 프레젠터와 뷰라는 클래스로 분리할 수 있다.
프레젠터와 뷰
뷰는 험블 객체이고 테스트하기 어렵다. 이 코드는 가능한한 간단하게 유지한다.
프레젠터는 테스트하기 쉬운 객체다. 어플리케이션으로부터 데이터를 받아 화면에 표시하기 적절한 포맷으로 변환하는 역할을 수행한다.
어플리케이션에서 화면에 날짜를 표시한다고 해보자. 어플리케이션이 프레젠터에 Date 객체를 전달한다. 그러면 프레젠터는 해당 데이터를 적절한 포맷의 문자열로 만들고, 뷰 모델이라고 부르는 간단한 데이터 구조에 담는다. 뷰는 뷰모델에서 이 데이터를 찾는다.
테스트와 아키텍처
테스트 용이성은 좋은 아키텍처가 지녀야할 속성인다, 험블 객체 패턴은 이를 잘 해결해준다.
테스트하기 쉬운 부분과 테스트하기 어려운 부분으로 아키텍처 경계가 정의되기 때문이다.
데이터베이스 게이트웨이
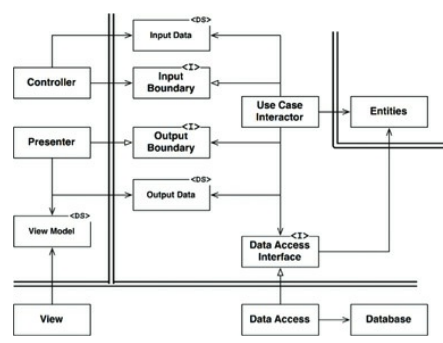
유스케이스 인터렉터와 데이터베이스 사이에는 데이터베이스 게이트웨이(위 그림의 Data Access Interface)가 위치한다.
이 게이트웨이는 다형적 인터페이스로, 어플리케이션이 데이터베이스에 수행하는 CRUD 작업과 관련된 모든 메서드를 포함한다.
이 인터페이스의 구현체는 데이터베이스 계층에 위치한다. 이 구현체는 험블 객체이다. 구현체에서 직접 SQL을 사용하여 데이터베이스에 접근한다.
인터랙터는 업무 규칙을 캡슐화 하기 때문에 험블 객체가 아니다. 따라서 테스트하기 쉬운데, 게이트웨이는 스텁(stub) 등의 테스트 더블(test-double)로 적당히 교체할 수 있다.
데이터 매퍼
ORM(Object Relational Mapper)은 어느 계층에 속하는가?
사실 객체라는 용어는 적합하지 않다. 객체는 데이터 구조가 아닌 메서드(오퍼레이션)의 집합이라고 볼 수 있다.
ORM보다는 데이터 매퍼(Data mapper)라는 표현이 더 정확해 보이는데, RDB로부터 가져온 데이터를 구조에 맞게 담아주기 때문이다.
이런 ORM은 게이트웨이 인터페이스와 데이터베이스 사이에서 일종의 또 다른 험블 객체 경계를 형성한다.
위 그림의 Data Access라고 볼 수 있을까?
서비스 리스너
어플리케이션이 다른 서비스와 통신해야 한다면 여기서 서비스 경계를 생성하는 험블 객체 패턴을 만들 수 있다.
어플리케이션이 데이터를 로드한 뒤 특정 모듈로 전달한다. 그러면 이 모듈은 적절한 포맷으로 만들어서 외부 서비스로 전송한다. 그 반대로 수신하는 경우도 마찬가지다.
결론
각 아키텍처 경계마다 경계 가까이에 있는 험블 객체 패턴을 발견할 수 있다. 테스트하기 어려운 무언가와 테스트하기 쉬운 무언가로 분리하여 전체 시스템의 테스트 용이성을 높일 수 있다.
Chapter 24. 부분적 경계
모든 선택에는 trade off가 따른다. 아키텍처 경계를 완벽하게 만드는데는 그만큼 비용이 많이든다.
인터페이스, 데이터 구조를 만들고 독립적으로 컴파일하고 배포할 수 있도록 격리하는데 필요한 모든 의존성도 관리해야한다. 코드량이 많아지고 유지하는데도 많은 노력이 든다.
뛰어난 아키텍트라면 경계를 명확히 만드는것이 효용대비 비용이 크다고 판단하면서도, 나중을 위해 경계에 필요한 공간을 확보해둘 수 있다.
이러한 경우에 부분적 경계를 고려해볼 수 있다.
마지막 단계를 건너뛰기
한가지 방법은 독립적으로 컴파일하고 배포할 수 있는 컴포넌트를 만들기 위한 작업은 모두 수행한 후, 단일 컴포넌트에 그대로 모아만 두는 것이다.
통신하는데 필요한 인터페이스, 데이터구조를 만들지만 단일 컴포넌트로 컴파일해서 배포한다.
작성해야하는 코드량은 완벽한 경계를 만들 때 만큼 필요하지만 다수의 컴포넌트를 관리하는 작업은 하지 않아도 된다.
일차원 경계
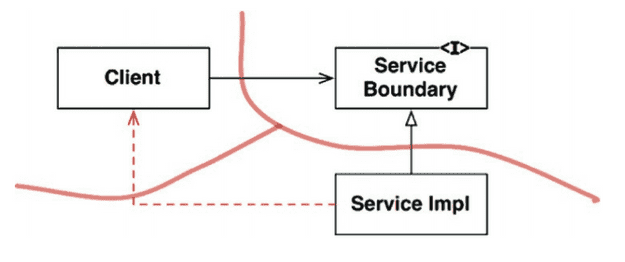
완벽한 형태의 아키텍처 경계는 양방향으로 격리된 상태를 유지하므로 쌍방향 인터페이스를 사용한다. 양방향으로 격리된 상태를 유지하려면 초기 작업량과 유지비용 모두가 많이 든다.
추후 완벽한 경계로 확장할 경우를 고려하면서도 단순한 형태를 유지하고자 할 때 위 그림과 같은 구조를 활용할 수 있다.
디자인 패턴중 전략 패턴(Strategy Pattern)의 형태로, ServiceBoundary 인터페이스는 클라이언트가 사용하며 ServiceImpl 클래스가 구현한다.
Client를 ServiceImpl로부터 격리시키는데 의존성 역전이 적용되어 있다. 쌍방향 인터페이스가 없고 개발자와 아키텍트가 주의를 기울이지 않는다면 점선처럼 비밀통로가 생길 수 있는 점은 단점이다.
퍼사드
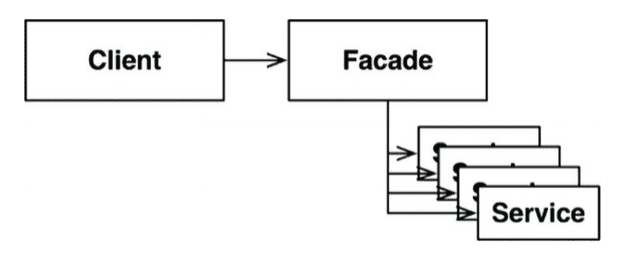
이보다 훨씬 더 단순한 경계는 퍼사드 패턴(Facade Pattern)으로, 의존성 역전까지도 희생하는 방법이다.
경계는 Facade 클래스로만 간단히 정의된다. Facade 클래스에서는 모든 서비스 클래스를 메서드 형태로 정의하고, 서비스 호출이 발생하면 해당 서비스 클래스로 호출을 전달한다.
하지만 Client가 모든 서비스 클래스에 대해 추이 종속성을 가지게 된다.
결론
아키텍처 경계를 부분적으로 구현하는 방법을 살펴봤다. 각각 나름의 비용과 장점을 지닌다.
이 외에도 방법은 많으며, 적절하게 사용할 수 있는 상황이 서로 다르다.
아키텍처 경계가 언제, 어디에 존재해야 할지, 그 경계를 완벽하게 구현할지 부분적으로 구현할지를 결정하는 일이 아키텍트의 역할 중 하나이다.
Chapter 25. 계층과 경계
지금까지는 시스템의 세가지 컴포넌트: UI, 업무 규칙, 데이터 베이스에 대해서만 이야기 했다. 하지만 대다수의 시스템에서 컴포넌트의 개수는 훨씬 더 많다.
간단한 컴퓨터 게임을 생각해보자. UI는 플레이어가 입력한 메시지를 게임 규칙으로 전달한다. 게임 규칙은 게임의 상태를 특정한 데이터 구조로 저장한다.
클린 아키텍처
사용자의 입력을 받는 UI가 다양한 언어를 지원하게 될 수 있다. 게임 규칙은 언어 독립적인 API를 사용해서 UI와 통신하고, UI는 API를 사람이 이해할 수 있는 언어로 변환한다.
또, 게임의 상태를 저장하는 곳이 플래시 메모리, 클라우드 혹은 단순한 RAM일 수 있다. 우리는 게임 규칙이 이러한 세부사항을 알지 않기를 바란다.
UI에서 변경의 축이 언어만이 아닐 수 있다. 사용자 입력을 받는 수단이 console, sms, shell등으로 전환될 수 있다.
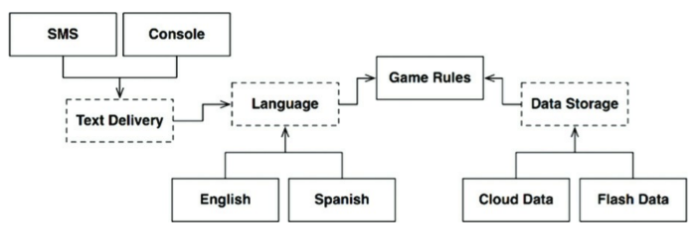
점선으로 된 테두리는 API를 정의하는 추상 컴포넌트를 가리킨다.
Language를 보면 Language가 정의하고 TextDelivery가 구현하는 API를 이용해 Text Delivery와 통신한다. API는 구현하는 쪽이 아닌 사용하는 쪽에 정의되고 소속된다. 의존성 흐름의 상위에 위치한 컴포넌트에 속하는 것이다.
English, SMS, CloudData와 같은 변형들은 추상 API 컴포넌트가 정의하는 인터페이스를 통해 제공되고, 실제 서비스하는 구체 컴포넌트가 구현한다.
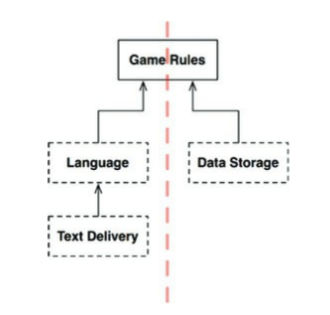
구체적인 변형들을 제외 하고 API에만 집중해보자.
데이터의 흐름을 생각해보면, 사용자의 모든 입력은 TextDelivery 컴포넌트부터 시작해 Language 컴포넌트를 거쳐 GameRules에서 처리하며, DataStorage에 적절한 현태로 저장된다.
그 후, GameRules는 Language로 출력을 내려보내고 TextDelivery를 통해 사용자에게 전달된다.
데이터 흐름이 두 부분으로 나뉘었다. 왼쪽은 사용자와의 통신에 관여하고, 오른쪽은 데이터 저장에 관여한다. GameRules는 두 흐름이 모두 거치는 최종적 처리기가 된다.
흐름 횡단하기
하지만 데이터 흐름은 항상 두가지가 아닐 수 있다. 이 게임을 네트워크 상에서 여러 사람이 플레이할 수 있게 만든다면 Network 관련 컴포넌트가 추가된다.
이 컴포넌트를 흐르는 데이터 또한 GameRules가 제어한다.
흐름 분리하기
모든 흐름이 결국에는 상단의 단일 정책 컴포넌트에서 만난다고 생각할 수 있다.
게임 규칙중 일부는 지도와 관련된 매커니즘을 처리할 수 있다. 길이나 장애물이 어떻게 구성되었는지 등의 정책을 담는다. (MoveManagement)
하지만 이보다 더 높은 수준에 또다른 정책 집합이 존재한다. 플레이어의 생명력, 퀘스트를 클리어하여 얻게 될 소득 등을 담고 있는 정책이다. (PlayerManagement)
이렇든 각기 다른 역할을 맡는 정책을 별도의 컴포넌트로 만들고, 경계를 그을 수 있다. (마이크로 서비스)
결론
간단한 게임을 만들더라도 아키텍처 경계를 고려할 수 있다는 점을 살펴보았다.
아키텍처 경계가 어디에 어떻게 필요한지 신중하게 파악하고, 이를 구현하는데 드는 비용과 이를 무시했을 때 추가되는 비용을 함께 고려할 수 있어야 한다.
추상화가 필요하다고 미리 예측해서는 안된다.(YAGNI) Over Engineering이 Under Engineering보다 나쁠 때가 훨씬 많다.
다른 한편으로는 경계가 필요하다는 사실을 뒤늦게 알아차린 후 이를 수정하는데 비용이 많이 들고 큰 위험을 감수해야한다.
이렇듯 아키텍트는 미래를 내다보고 현명하게 추측하고 비용을 산정하고 결정해야한다.
프로젝트 초반에는 구현할 경계가 무엇인지 쉽게 결정할 수 없다. 프로젝트 발전과정을 지켜보며 주의를 기울여야 한다.
Chapter 26. 메인(Main) 컴포넌트
모든 시스템에는 최소한 하나의 컴포넌트가 존재하고, 이 컴포넌트가 나머지 컴포넌트를 생성하고, 조정하며, 관리한다.
궁극적인 세부사항
메인 컴포넌트는 궁극적인 세부사항으로, 가장 낮은 수준의 정책이다.
메인은 시스템의 초기 진입점이다. 그 어떤 컴포넌트도 메인에 의존하지 않는다.
메인은 모든 팩토리(Factory), 전략(Strategy), 그리고 시스템 전반을 담당하는 설정들을 생성한 후 더 높은 수준의 컴포넌트로 제어권을 넘기는 역할을 한다.
의존성을 주입하는 일은 바로 이 메인 컴포넌트에서 이루어진다.
앞장에서 살펴본 게임 어플리케이션의 메인 컴포넌트를 살펴보자.
public class Main implements HtwMessageReceiver {
private static HuntTheWumpus game;
private static int hitPoints = 10;
private static final List<String> caverns = new ArrayList<>();
private static final String[] environments = new String[] {
'bright', 'humid', 'dry', // ...
};
private static final String[] shapes = new String[] {/*...*/};
// ...
public static void main(String[] args) throws IOException {
game = HtwFactory.makeGame('htw.game.HuntTheWumpusFacade', new Main());
createMap();
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
game.makeRestCommand().execute();
while (true) {
System.out.println(game.getPlayerCavern());
System.out.println('Health: ' + hitPoints + " arros: " + game.getQuiver());
HuntTheWumpus.Command c = game.makeRestCommand();
String command.br.readLine();
if(command.equalsIgnoreCase('e'))
c = game.makeMoveCommand(EAST);
// ...
}
}
private static void createMap() {
while (/**/)
carvns.add(makeName())
for (String cavern : caverns) {
maybeConnectCavern(cavern, NORTH);
// ...
}
}
}
}
main 컴포넌트에서는 문자열을 로드하는 방법으로 코드의 나머지 핵심 영역에서 구체적인 문자열을 알지 못하도록 만들었다.
main 함수에서는 더 지저분한 htw.game.HuntTheWumpusFacade 클래스에 의존하지 않기 위해 문자열 형태로 언급하였다.
입력 스트링 생성, 게임의 메인 루프 처리, 간단한 명령어 해석, 지도 생성 등을 모두 main 함수에서 처리하고 있다. 하지만 명령어를 실제로 처리하는 일은 다른 고수준 컴포넌트로 위임한다는 사실이 중요하다.
메인은 고수준의 시스템을 위한 모든것을 로드한 후, 제어권을 고수준의 시스템에게 넘긴다.
결론
메인을 어플리케이션의 플러그인이라고 생각하자. 초기 조건들을 설정하고 외부 자원을 모두 수집한 후 제어권을 어플리케이션의 고수준 정책으로 넘기는 플러긴이다.
개발용 메인, 테스트용 메인, 프로덕션용 메인, 국가별, 고객별 메인을 만들어 바꿔 끼울 수 있다.
메인은 교체가능한 플러그인으로, 아키텍처 경계 바깥에 위치한다고 볼 수 있다.