[기술서적 리뷰] Clean Architecture - 3. 설계 원칙 (SOLID)
좋은 소프트웨어를 만드는 것은 튼튼한 것물을 짓는 것과 같다.
좋은 벽돌을 사용하지 않으면 빌딩의 아키텍처가 좋은 것은 큰 의미가 없다. 반대로 좋은 벽돌을 사용하더라도 빌딩의 아키텍처를 엉망으로 만들 수 있다.
좋은 벽돌로 좋은 아키텍처의 건물을 짓듯이 좋은 코드로 좋은 소프트웨어를 설계하는 원칙이 필요한데, 이것이 SOLID이다.
SOLID 원칙은 함수와 데이터 구조를 클래스로 배치하는 방법, 이들 클래스를 결합하는 방법을 설명해준다. 객체 지향 소프트웨어에만 적용되는 것은 아니며 함수와 데이터를 결합한 어떤 구조에도 적용할 수 있다.
SOLID 원칙의 목적은 코드 - 모듈 - 컴포넌트 - 아키텍처로 이어지는 소프트웨어 추상 수준에서 중간수준(모듈, 컴포넌트 내부)의 소프트웨어 구조가 아래와 같도록 만드는 데 있다.
- 변경에 유연하다
- 이해하기 쉽다.
- 많은 소프트웨어 시스템에 사용될 수 있는 컴포넌트의 기반이 된다.
SOLID
- SRP: 단일 책임 원칙, Single Responsibility Principle
- 각 소프트웨어 모듈은 변경 이유가 하나여야만 한다.
- OCP: 개방-폐쇄 원칙, Open-Closed Principle
- 기존 코드를 수정하기보단 추가하는 방식으로 설계해야만 시스템을 쉽게 변경할 수 있다.
- LSP: 리스코프 치환 원칙, Liskov Substitution Principle
- 상호 대체 가능한 구성요소를 이용하여 시스템을 만드려면, 이 구성요소들은 반드시 치환 가능해야 한다.
- ISP: 인터페이스 분리 원칙, Interface Segregation Principle
- 사용하지 않는 것에 의존하지 않아야 한다.
- DIP: 의존성 역전 원칙, Dipendency Inversion Principle
- 고수준 정책을 구현하는 코드는 저수준 세부사항을 구현하는 코드에 절대로 의존하면 안된다.
Chapter 7. SRP: 단일 책임 원칙
단 하나의 일만 해야한다는 원칙은 SRP가 아니며, 저수준 코드 단계의 함수에 해당하는 원칙이다.
단일 모듈은 변경의 이유가 하나, 오직 하나여야 한다.
소프트웨어 시스템은 사용자와 이해관계자를 만족시키기 위해 변경된다. 따라서 다음과 같이 바꿔 쓸 수 있다.
단일 모듈은 오직 하나의 사용자 또는 이해관계자에 대해서만 책임져야 한다.
- 사용자(이해관계자): 개별 사람이라기 보단 변경을 요청하는 집단(액터, Actor)을 의미한다.
- 모듈: 함수와 데이터 구조로 구성된 응집된 집합이다. 이는 언어에 따라 단일 소스 파일일 수도, 클래스일 수도 있다.
잘못된 사례 1: 우발적 중복
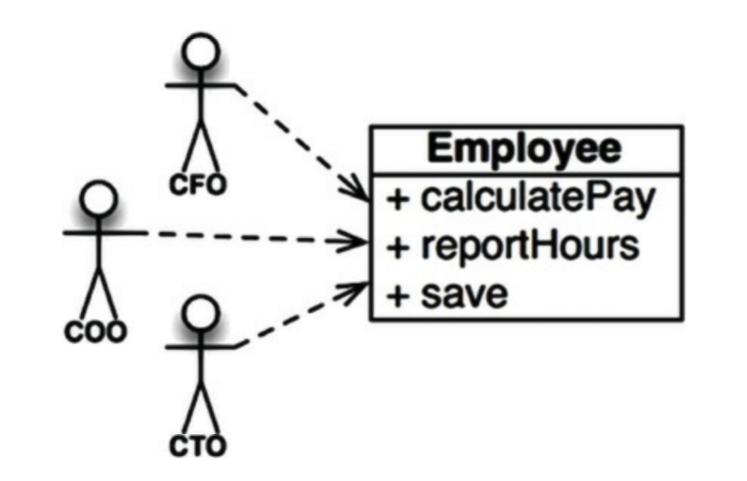
급여 어플리케이션의 Employee 클래스를 생각해보자.
- calculatePay(): 회계팀에서 기능을 정의하며, CFO 보고를 위해 사용한다.
- reportHours(): 인사팀에서 기능을 정의하며, COO 보고를 위해 사용한다.
- save(): DBA가 기능을 정의하며, CTO 보고를 위해 사용한다.
개발자가 이 세 메서드를 Employee라는 단일 클래스에 배치하여 세 액터가 결합되어 버렸다.
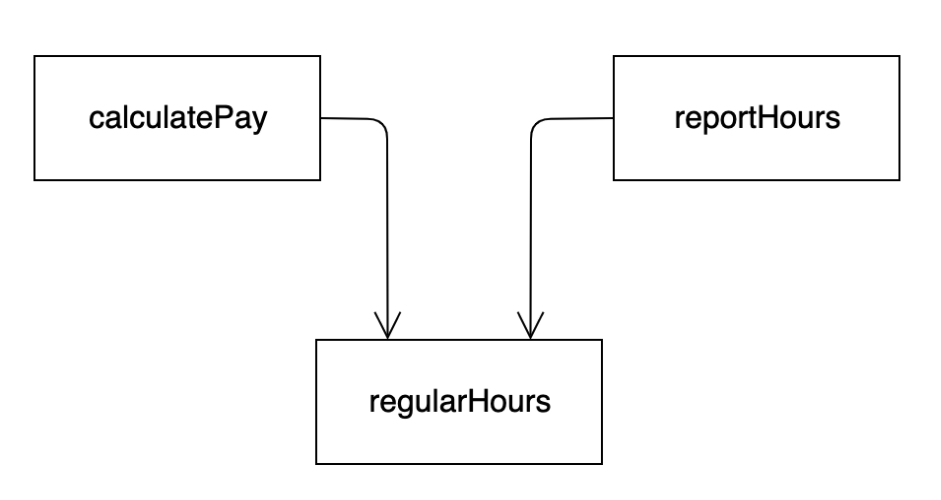
CFO 팀에서 결정한 조치가 COO 팀이 의존하는 무언가에 영향을 줄 수 있다. 두 함수는 업무 시간을 계산하는 regularHours() 메서드를 공유한다고 해보자.
CFO 팀에서 업무 시간을 계산하는 방식을 약간 수정하기로 결정했는데, COO 팀은 근무시간을 다른 목적으로 사용하기 때문에 이 변경을 원치 않을 수 있다.
개발자는 calculatePay() 메서드를 분석한 후 regularHours()를 수정한다. 하지만 reportHours()에서도 이 메서드를 호출한다는 것을 눈치채지 못한다. CFO 팀은 새 메서드를 테스트하고, 배포한다.
COO 팀은 reportHours() 메서드가 생성한 보고서를 여전히 이용한다. 오류가 발견되고, COO는 격노한다.
이와 같은 상황은 서로 다른 액터가 의존하는 코드를 한 데 배치했기 때문이며, 따라서 SRP 원칙이 필요하다.
잘못된 사례 1: 병합
한 모듈에 많은 메서드를 포함하면 병합이 자주 발생하는 것은 당연하다. 특히 이들 메서드가 서로 다른 액터를 책임진다면 병합이 발생할 가능성은 더 높아진다.
CTO 팀에서 Employee 테이블 스키마를 수정하기로 결정하고, COO 팀에서 reportHours() 메서드의 보고서 형식을 변경하기로 결정하는 경우를 생각해 보자.
두 명의 서로 다른 개발자가 Employee 클래스에 변경사항을 적용하기 시작한다. 이 변경사항은 서로 충돌하며 병합이 발생한다.
최근 사용되는 코드 버전 관리 시스템 도구들은 뛰어나지만 병합이 발생하는 모든 경우를 해결할 수 없다. 항상 위험이 뒤따른다.
이 문제를 벗어나는 방법은 서로 다른 액터를 뒷받침하는 코드를 서로 분리하는 것이다.
해결책
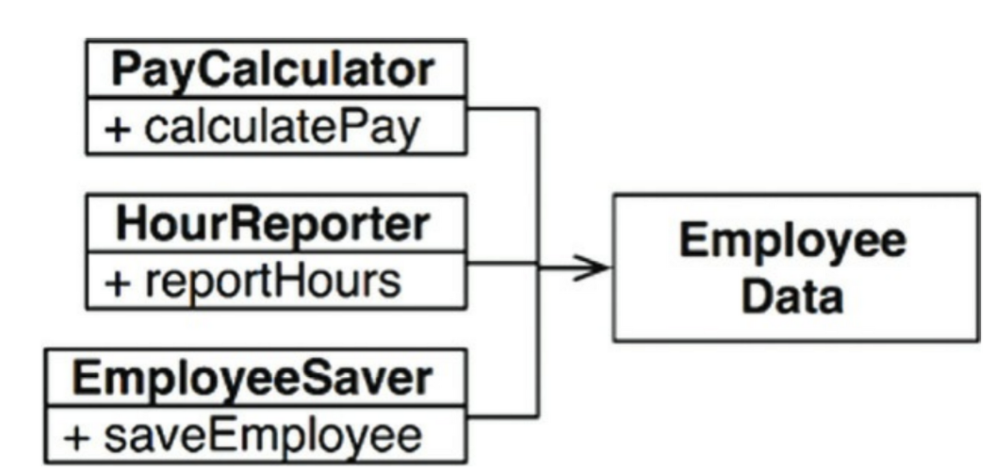
가장 확실한 해결책은 데이터와 메서드를 분리하는 방식이다. 데이터만을 가지는 EmployeeData 클래스를 만들고, 각 메소드를 가지는 세개의 클래스가 공유하도록 한다(왼쪽 그림). 세 클래스는 서로의 존재를 몰라야 한다.
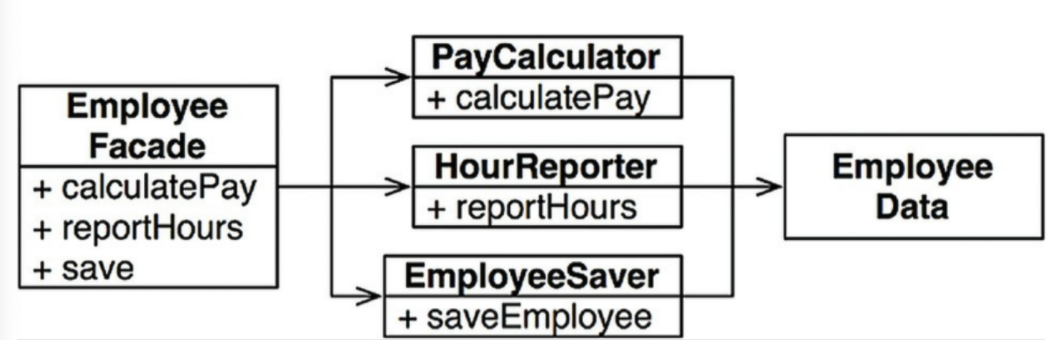
세 클래스를 인스턴스화 하고 추적해야 하는 것이 불편하다면 퍼사드(Facade) 패턴을 사용할 수 있다(오른쪽 그림). EmployFacade는 코드는 거의 없이 세 클래스의 객체를 생성하고, 요청된 메서드를 가지는 객체로 위임하는 일을 책임진다.
Facade는 “건물의 정면”을 의미하는 단어로 어떤 소프트웨어의 다른 커다란 코드 부분에 대하여 간략화된 인터페이스를 제공해주는 디자인 패턴
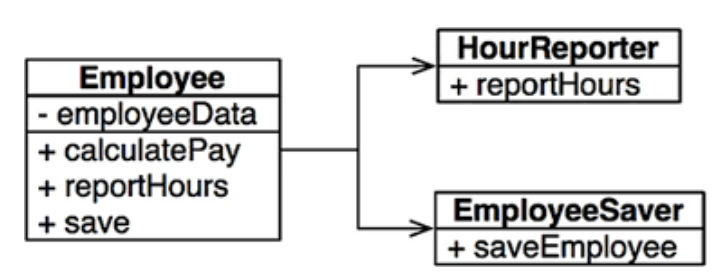
가장 중요한 업무 규칙을 데이터와 가깝게 배치하는 방식을 선호할 수도 있다. 가장 중요한 메서드들은 Employee 클래스에 유지하되, Employee 클래스를 덜 중요한 나머지 메서드들에 대한 퍼사드로 사용할 수도 있다.
결론
SRP는 메서드와 클래스 수준의 원칙이다. 하지만 이보다 상위 두 수준에서 다른형태로 다시 등장한다. 컴포넌트 수준에서는 공통 폐쇄 원칙(Common Closure Principle), 아키텍처 수준에서는 아키텍처 경계(Architecture Boundary)의 생성을 책임지는 변경의 축이 된다.
Chapter 8. OCP: 개방-폐쇄 원칙
소프트웨어 개체는 확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.
소프트웨어 개체의 행위는 확장할 수 있어야 하지만, 이때 개체를 변경해서는 안된다.
만약 요구사항을 살짝 확장하는데 소프트웨어 또는 코드를 엄청나게 수정해야 한다면 이는 잘 설계된 아키텍처가 아니다.
사고 실험
재무 데이터를 읽어와 보고서용 재무 데이터를 생성하여 웹 페이지로 보여주는 시스템을 생각해 보자. 웹 페이지에 표시되는 데이터는 스크롤, 음수 빨간색 표시등의 기능이 있다.
동일한 정보를 흑백 프린터 형태로 출력해달라는 요구사항을 받았다. 페이지번호, 머리글 바닥글 등 새로운 기능들이 필요하다.
새로운 코드를 작성해야한다. 기존 코드는 얼마나 많이 수정해야 할까?
소프트웨어 아키텍처가 훌륭하다면 이상적인 변경량은 0이다.
서로 다른 목적으로 변경되는 요소를 분리하고(SRP), 요소 사이의 의존성을 체계화함으로써(DIP) 변경량을 최소화 할 수 있다.
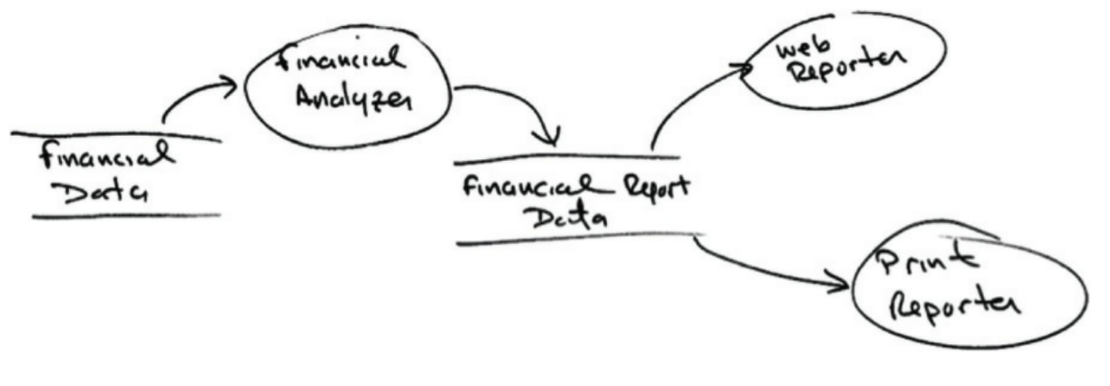
SRP 원칙을 사용하여 데이터 흐름을 위와 같은 형태로 만들 수 있다.
재무 데이터 검사 -> 보고서용 데이터 생성 -> 보고서 생성
보고서용 데이터를 계산하는 책임과, 보고서를 생성하는 책임 두가지가 분리되어 있는 것이 핵심이다. 두 책임 중 하나에서 변경이 발생하더라도 다른 하나는 변경되지 않도록 소스 코드 의존성을 조직화해야 한다.
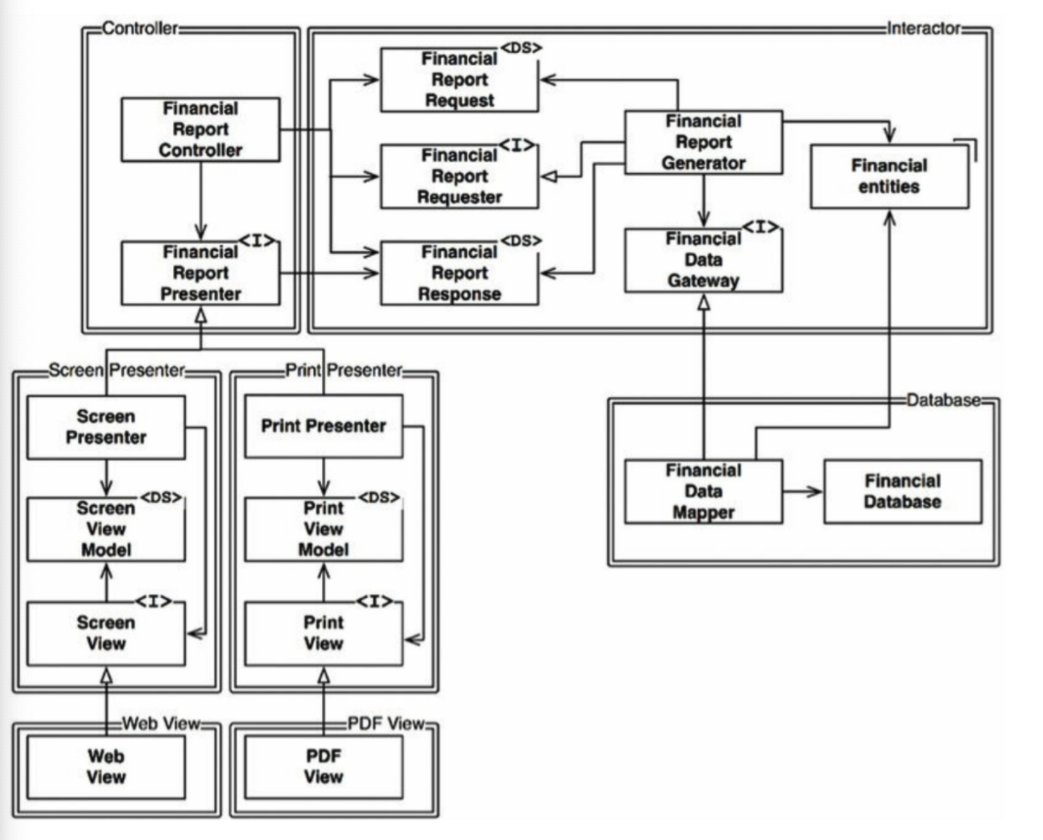
처리 과정을 클래스 단위로 분할 하고 이 클래스 들을 컴포넌트 단위(이중선)으로 구분하였다.
<I>로 표시된 클래스는 인터페이스이며 <DS>로 표시된 클래스는 데이터 구조이다. 화살표가 열려 있다면 사용관계이며, 닫혀 있다면 구현 또는 상속 관계이다.
이 화살표는 의존성의 방향을 나타내며, 소스 코드 의존성의 방향도 동일하다. 모든 컴포넌트의 관계는 단방향으로만 연결된다.
A 컴포넌트에서 발생한 변경으로부터 B 컴포넌트를 변경하려면 A가 B에 의존해야 한다.
Prensenter에서 발생한 변경으로부터 Controller를 보호하고, View에서 발생한 변경으로부터 Presenter를 보호하였다. Interactor는 다른 모든 것에서 발생한 변경으로부터 보호하고 있다.
Interactor가 업무규칙을 포함하기 때문이다. 어플리케이션에서 가장 높은 수준의 정책을 포함한다. 가장 중요한 문제를 다루는 것이다.
저수준(덜 중요한) 컴포넌트에서 발생한 변경으로부터 고수준(더 중요한) 컴포넌트를 보호하는 것이 아키텍처 수준에서 OCP가 동작하는 방식이다.
위에서 말한 요구사항대로 새로운 Presenter가 추가될 때마다 더 중요한 Controller의 코드는 변경될 필요가 없으니 확장에는 열려있고, 변경에는 닫혀있다고 할 수 있다.
방향성 제어흐름
FinancialDataGateway 및 FinancialREportPresenter 인터페이스는 컴포넌트간의 의존성을 역전시키기 위해 설계되었다.
정보 은닉
FinancialReportRequester 인터페이스는 Controller가 Interactor 내부에 대해 너무 많이 알지 못하도록 막기 위해 설계 되었다. Controller에서 발생한 변경으로 부터 Interactor를 보호하는 일도 중요하지만 Interactor에서 발생한 변경으로부터 Controller도 보호되기를 바랬다.
결론
OCP의 목표는 시스템을 확장하기 쉬운 동시에 변경으로 인해 너무 많은 영향을 받지 않도록 하는데 있다. 이를 위해서 시스템을 컴포넌트 단위로 분리하고, 수준에 따라 의존성 방향을 제어한다.
Chapter 9. LSP: 리스코프 치환 원칙
S 타입의 객체(o1), 각각에 대항하는 T 타입 객체(o2)가 있고, T 타입을 이용해서 정의한 모든 프로그램 P에서 o2의 자리에 o1을 치환하더라도 P의 행위가 변하지 않는다면, S는 T의 하위 타입이다.
무슨말인지 모르겠다.
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.
조금은 이해가 간다. 예제를 살펴보자.
상속을 사용하도록 가이드하기 (원칙 준수)
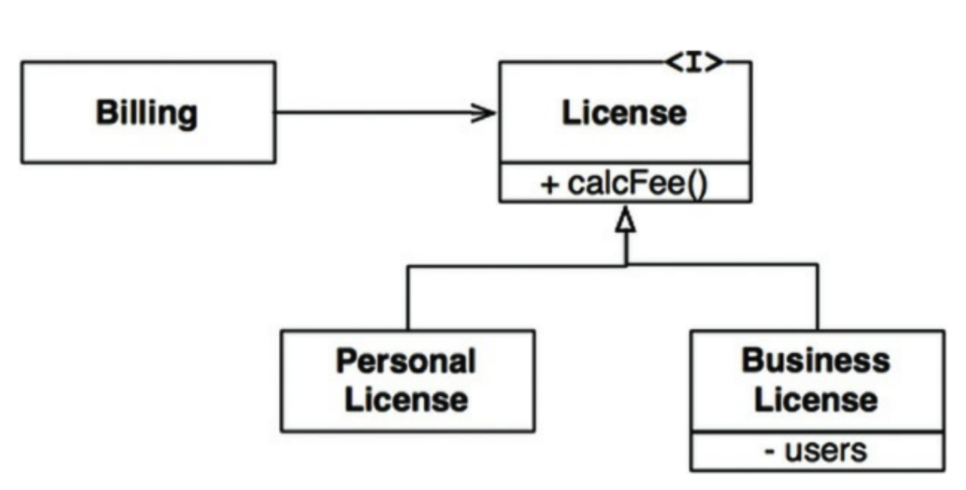
License라는 클래스는 calcFee()라는 메서드를 가지며, Billing 어플리케이션에서 이 메서드를 호출한다. License의 두 하위 타입은 서로 다른 알고리즘을 이용하여 라이선스 비용을 계산한다.
Billing 어플리케이션의 행위가 License 하위 타입 중 무엇을 사용하는지에 전혀 의존하지 않기 떄문에 LSP를 준수한다고 할 수 있다. 하위 타입이 모두 상위 타입을 치환할 수 있는 것이다.
// Billing
License license = new LicenseFactory();
license.calcFee();
// 치환
PersonalLicense license = new LicenseFactory();
license.calcFee();
정사각형 문제 (원칙 위배)
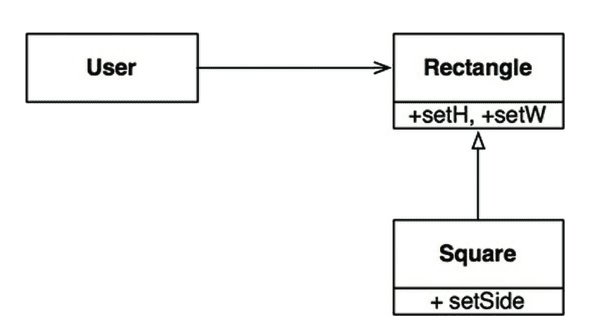
Square는 Rectangle의 하위 타입으로 적합하지 않은데, Rectangle의 높이와 너비는 서로 독립적이지만 Square의 높이와 너비는 반드시 함께 변경되기 때문이다.
Rectangle r = rectangleFactory() // Square
r.setW(5)
r.setH(2)
assert(r.area() == 10); // 실패
LSP와 아키텍처
LSP를 준수하기 위해 앞의 예시와 같은 상속뿐만 아니라 인터페이스를 이용할 수도 있다.
사용자들은 잘 정의된 인터페이스와 그 인터페이스 구현체 끼리의 상호 치환 가능성을 기대하고 있을 것이기 때문이다.
택시 파견 서비스 (원칙 위배)
다양한 택시 회사들을 엮어 택시 파견 서비스를 만들고 있다고 해보자.
고객은 어느 택시 업체인지 알 필요 없이 자신의 상황에 가장 적합한 택시를 찾는다. 고객이 택시를 선택하면 시스텀은 API 호출을 통해 택시를 고객에게 보낸다.
택시 기사인 Bob을 파견하기 위한 URI는 다음과 같다.
purplecab.com/driver/Bob
시스템은 출발지, 도착지 등 다른 정보를 덧붙인 후 호출한다.
purplecab.com/driver/Bob
/pickupAddress/24 Maple St
/pickupTime/153
/destination/ORD
그런데 업계 1위 택시회사인 애크미의 개발자가 스펙을 고려하지 못한채 URI를 변경하였다고 해보자. destination 필드를 dest로 축약하는 것으로 변경했다.
if (driver.getDispatchUri().startsWith("acme.com").....
if 문장을 추가하여 택시 업체에 따른 분기를 해주어야 한다. 애크미가 더 성장해서 다른 택시 회사를 인수한다면 if문은 계속 추가될 것이다.
서비스들의 인터페이스가 치환 가능하지 않은 경우 어떤일이 일어나는지 생각해보았다.
결론
LSP는 아키텍처 수준까지 확장할 수 있다. 치환 가능성이 위배되면 시스템 아키텍처가 오염되어 상당량의 작업을 추가해야 한다.
Chapter 10. ISP: 인터페이스 분리 원칙
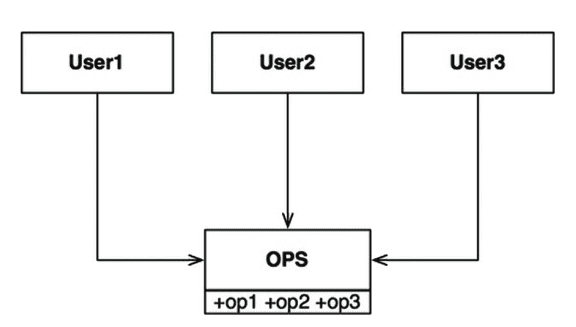
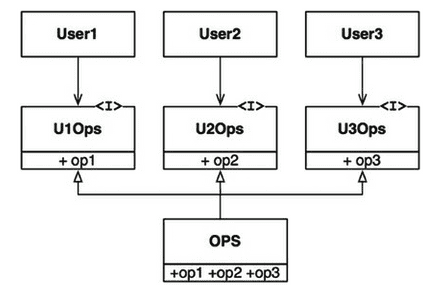
User1은 op1(), User2는 op2(), User3는 op3() 메서드만을 사용한다고 가정해보자.
(OPS가 정적 타입 언어로 작성된 클래스라면) User1은 op2와 op3를 전혀 사용하지 않음에도 OPS의 소스코드가 변경될 때마다 항상 User1도 다시 컴파일 한 후 배포해야 한다(왼쪽 그림).
OPS를 인터페이스 단위로 분리하여 해결할 수 있다(오른쪽 그림).
ISP와 언어
위 사례는 프로그래밍 언어에 의존한다. 동적 타입 언어에서는 런타임에 타입 추론이 발생하므로 재컴파일과 재배포가 필요 없을 수 있다.
ISP와 아키텍처
ISP를 사용하는 근본적인 동기를 살펴보면, 잠재된 우려사항을 볼 수 있다.
일반적으로 필요 이상으로 많은 걸 포함하는 모듈에 의존하는 것은 해로운 일이다.
System S -> Framework F -> Database D
위와 같은 방향으로 의존하고 있는 시스템에서 F, S와는 전혀 관계 없는 기능이 D에 포함될때, 그 기능 때문에 D 내부가 변경되면 F 또는 S 까지 재배포 해야할지 모른다.
결론
자신이 사용하지 않는 무엇인가에 의존하면 예상치 못한 문제에 빠질 수 있다.
Chapter 11. DIP: 의존성 역전 원칙
DIP에서 추구하는 유연성이 극대화된 시스템이란,
소스 코드 의존성이 추상(abstract)에 의존하며 구체(concretion)에는 의존하지 않는 시스템이다.
use, import, include 같은 구문은 오직 인터페이스나 추상 클래스만을 참조해야 하는 것이다.
하지만 모든 경우에 해당하는 것은 아니다.
자바의 String 클래스는 구체 클래스이지만 변경되는 일이 거의 없고, 있더라도 엄격하게 통제된다. 의존할만 하다.
우리가 의존하지 않고자 하는 것은 변동성이 큰 구체이다.
안정된 추상화
인터페이스도 변경되는 경우가 있지만 구현체보다 변동성이 낮다.
뛰어난 아키텍트라면 인터페이스의 변동성을 낮추기 위해 애쓴다. 인터페이스 대신 구현체를 변경하여 기능을 추가하는 방법을 찾기 위해 노력한다.
구체적인 코딩 실천법으로 요약할 수 있다.
- 변동성이 큰 구체 클래스를 참조하지 말라.
- 대신 추상 인터페이스를 참조하라. 추상 팩토리(Abstract Factory)를 사용하라.
- 변동성이 큰 구체 클래스로부터 파생하지 말라.
- 상속은 가장 뻣뻣해서 변경하기 어렵다. (why?)
- 구체 함수를 오버라이드 하지말라.
- 구체 함수는 소스 코드 의존성을 포함하는 경우가 많다. 구체 함수를 오버라이드 하면 이러한 의존성을 제거할 수 없게 되며, 의존성을 상속하게 된다.
- 구체적이며 변동성이 크다면 절대로 그 이름을 언급하지 말라.
- DIP의 원칙을 다른말로 표현한 것이다.
팩토리
객체를 생성하려면 해당 객체를 정의한 코드를 호출하는 것이 필요하다.
이를 해결하기 위해 추상 팩토리를 사용하곤 한다.
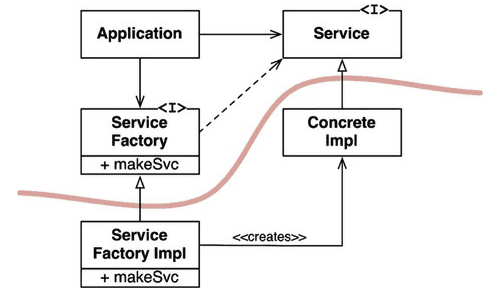
Application은 (Service 인터페이스를 통해) ConcreteImpl을 사용하므로 어떤식으로든 ConcreteImpl 인스턴스를 생성해야 한다.
public class ServiceFactory {
public static Concrete makeSvc(ConcreteId concreteId) {
Monitor instance = null;
switch (concreteId) {
case 1:
instance = new Concrete1();
break;
case 2:
instance = new Concrete2();
break;
}
return instance;
}
}
// Application
Concrete instance = ServiceFactory.makeSvc(/**/);
비교적 저수준인 ConcreteImpl를 의존하지(언급하지) 않기 위해 ServiceFactory 인터페이스의 makeSvc 메서드를 호출한다.
곡선은 아키텍처 경계를 뜻하며 구체적인 것들로부터 추상적인 것들을 분리한다. 소스 코드 의존성은 해당 곡선과 교차할 때 모두 단 방향으로 향한다.
곡선이 분리한 두 컴포넌트 중 추상 컴포넌트는 어플리케이션의 고수준 업무 규칙을 포함한다. 구체 컴포넌트는 업무 규칙을 다루기 위해 필요한 모든 세부사항을 포함한다.
제어 흐름은 소스 코드 의존성과는 정반대 방향으로 흐른다. (Application에서 구체 인스턴스 생성) 이러한 이유로 이 원칙을 의존성 역전이라고 부른다.
구체 컴포넌트
그림에서 두개의 구체 컴포넌트에는 의존성이 남아있다. DIP 위배를 모두 없앨 수 는 없지만 DIP를 위배하는 클래스들은 적은 수의 구체 컴포넌트 내부로 모을 수 있다. 이를 통해 시스템의 나머지 부분과는 분리할 수 있는 것이다.
대다수의 시스템은 이런 구체 컴포넌트를 최소한 하나는 포함하는데, 흔히 이 컴포넌트를 메인(Main)이라고 부른다.
위 그림과 같은 경우라면 main 함수는 ServiceFactoryImpl의 인스턴스를 생성한 후, 이 인스턴스를 ServiceFactory 타입으로 전역변수에 저장할 것이다. 그런 다음 Application은 이 전역 변수를 이용해서 ServiceFactoryImpl의 인스턴스에 저장할 것이다.
결론
고수준의 아키텍처 원칙에서 DIP는 가장 눈에 드러나는 원칙이다. 위 그림의 곡선은 이후의 장에서는 아키텍처간의 경계가 될것이다.